



Key Takeaway
- Robots.txt คือไฟล์ข้อความที่วางไว้ในโฟลเดอร์รากของเว็บไซต์ ใช้บอก Search Engine ว่าควรหรือไม่ควรเข้าถึงหน้าเว็บไซต์หรือโฟลเดอร์ใดบ้าง
- Robots.txt มีหลักการทำงาน โดยบอตจะอ่านคำสั่งในไฟล์ก่อนเข้าค้นหาหน้าเว็บ ตามคำสั่ง Allow หรือ Disallow เพื่อจัดการการเข้าถึงอย่างมีระเบียบ
- Robots.txt สำคัญต่อ SEO เพราะช่วยควบคุม Crawl Budget ป้องกันเนื้อหาซ้ำ และทำให้บอตโฟกัสหน้าที่สำคัญ ส่งผลให้เว็บไซต์ถูกจัดทำดัชนีอย่างมีประสิทธิภาพ
- ข้อควรระวังในการใช้ Robots.txt คือไม่ควรใช้ซ่อนข้อมูลสำคัญ ระวังบล็อกหน้าสำคัญโดยไม่ตั้งใจ และควรทดสอบไฟล์ก่อนใช้งานจริงเพื่อป้องกันปัญหาการจัดทำดัชนี
เคยสงสัยไหมว่าเวลาที่เราค้นหาเว็บไซต์ใน Google แล้วทำไมบางหน้าเว็บไซต์ถึงไม่โผล่ขึ้นมา ทั้งที่เราก็เห็นอยู่ในเว็บไซต์ทุกวัน? เบื้องหลังเรื่องนี้มีตัวช่วยลับๆ ที่หลายคนอาจมองข้าม นั่นคือ ‘Robots.txt’ ไฟล์เล็กๆ แต่ทรงพลังที่อยู่ในโฟลเดอร์รากของเว็บไซต์
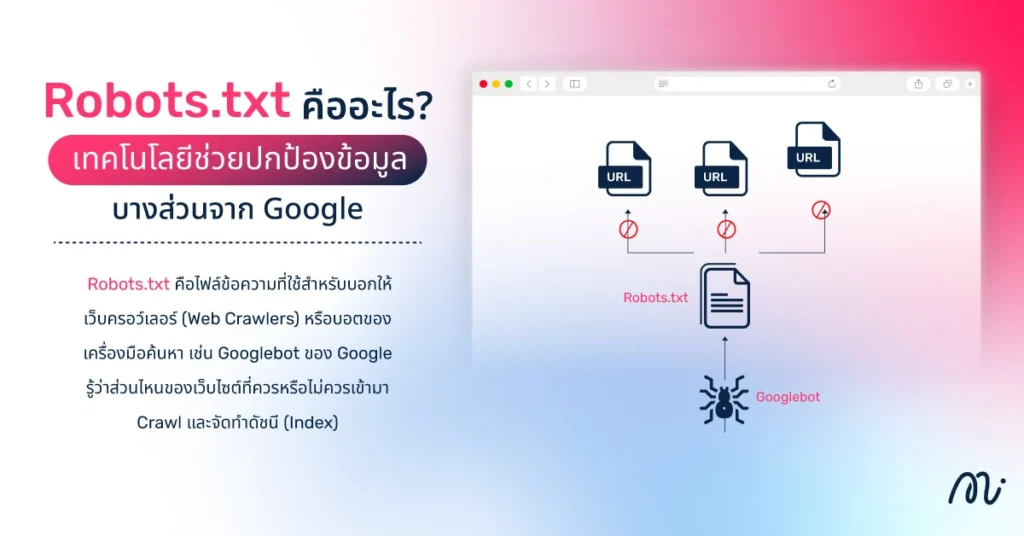
Robots.txt คือไฟล์ข้อความที่วางไว้ในโฟลเดอร์ราก (Root Directory) ของเว็บไซต์ เพื่อบอก Search Engine ว่าควรหรือไม่ควรเข้าถึง (Crawl) หน้าเว็บไซต์หรือโฟลเดอร์ไหนบ้าง เหมือนเป็นป้ายบอกทางสำหรับบอต ที่ช่วยให้เว็บไซต์ถูกจัดการอย่างเป็นระเบียบและปลอดภัยมากขึ้น มาทำความรู้จัก Robots.txt กันในบทความนี้เลย!
Robots.txt คืออะไร? เทคโนโลยีช่วยปกป้องข้อมูลบางส่วนจาก Google
บางครั้งเวลาที่เราเข้าเว็บไซต์ อาจไม่อยากให้ทุกหน้าของเว็บไซต์ถูกค้นพบโดย Google หรือเครื่องมือค้นหาอื่นๆ ซึ่งนี่เองคือหน้าที่ของ Robots.txt คือไฟล์ข้อความที่ใช้สำหรับบอกให้เว็บครอว์เลอร์ (Web Crawlers) หรือบอตของเครื่องมือค้นหา เช่น Googlebot ของ Google รู้ว่าส่วนไหนของเว็บไซต์ที่ควรหรือไม่ควรเข้ามา Crawl และจัดทำดัชนี (Index)
ไฟล์นี้เหมือนเป็นคู่มือสั้นๆ ที่บอตอ่านแล้วรู้ว่าหน้าไหนเปิดเผยได้ หน้าไหนควรเก็บไว้เป็นส่วนตัว ทำให้เจ้าของเว็บไซต์ควบคุมการมองเห็นข้อมูลได้ง่ายขึ้น และช่วยจัดการเว็บไซต์ให้อ่านง่ายสำหรับ Search Engine ด้วย

Robots.txt ทำงานอย่างไร? จากคำสั่งง่ายๆ สู่ผลลัพธ์ที่ยิ่งใหญ่
การทำงานของ Robots.txt ไม่ซับซ้อนเลย แค่เราเขียนคำสั่งบอกบอตว่า “อนุญาตให้เข้าหน้านี้” หรือ “ห้ามเข้าหน้านี้” บอตของ Search Engine อย่าง Google จะอ่านไฟล์นี้ก่อนเริ่มเข้าค้นหาข้อมูลในเว็บไซต์ จากนั้นจะปฏิบัติตามคำสั่งที่กำหนดไว้ ทำให้บางหน้าถูกจัดทำดัชนี ขณะที่บางหน้าถูกเก็บเป็นส่วนตัว การมีไฟล์ Robots.txt จึงเหมือนการวางป้ายบอกทางให้บอต ทำให้เว็บไซต์ถูกจัดการอย่างเป็นระเบียบ ปลอดภัย และมองเห็นข้อมูลสำคัญได้เหมาะสม
ตัวอย่าง Robots.txt ที่พบบ่อย
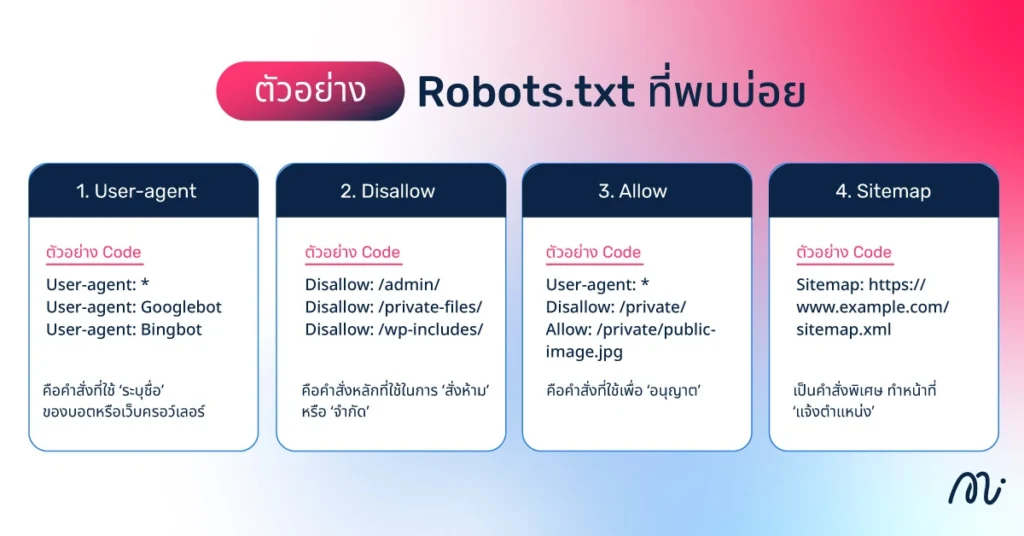
แม้ไฟล์ Robots.txt จะมีขนาดเล็ก แต่ภายในกลับเต็มไปด้วยคำสั่งสำคัญที่ช่วยควบคุมพฤติกรรมของบอตจาก Search Engine แต่ละตัว ต่อไปคือคำสั่งพื้นฐานที่มักพบในไฟล์ Robots.txt พร้อมตัวอย่างและคำอธิบาย เพื่อให้เห็นภาพว่าทำงานอย่างไรในเว็บไซต์
1. User-agent
ตัวอย่าง Code
User-agent: *
User-agent: Googlebot
User-agent: Bingbot
User-agent คือคำสั่งที่ใช้ ‘ระบุชื่อ’ ของบอตหรือเว็บครอว์เลอร์ที่คำสั่งถัดไปมีผลบังคับใช้ โดยทั่วไปบอตของเครื่องมือค้นหาแต่ละรายจะมีชื่อเฉพาะ เช่น Googlebot สำหรับ Google หรือ Bingbot สำหรับ Bing หากคุณต้องการให้คำสั่งมีผลกับบอตทุกตัว ให้ใช้เครื่องหมาย ดอกจัน (*) ซึ่งหมายถึง ‘บอตทั้งหมด’ การระบุ User-agent เป็นขั้นตอนแรกสุดในการกำหนดค่า Robots.txt ที่ถูกต้อง
2. Disallow
ตัวอย่าง Code
Disallow: /admin/
Disallow: /private-files/
Disallow: /wp-includes/
Disallow คือคำสั่งหลักที่ใช้ในการ ‘สั่งห้าม’ หรือ ‘จำกัด’ ไม่ให้บอตที่ระบุใน User-agent ก่อนหน้า เข้าสแกนไดเรกทอรี (Directory) โฟลเดอร์ หรือไฟล์ที่ระบุตามหลัง บอตที่เชื่อฟังคำแนะนำนี้จะไม่ใช้ Crawl Budget ไปกับส่วนที่ไม่สำคัญหรือส่วนที่ไม่ต้องการให้ปรากฏในผลการค้นหา หากต้องการอนุญาตให้สแกนทุกส่วน ให้ใช้ Disallow: โดยไม่มีเครื่องหมายทับ / ตามหลัง
3. Allow
ตัวอย่าง Code
User-agent: *
Disallow: /private/
Allow: /private/public-image.jpg
Allow คือคำสั่งที่ใช้เพื่อ ‘อนุญาต’ ให้บอตสแกนไฟล์หรือไดเรกทอรีย่อยที่ระบุ แม้ว่าไดเรกทอรีหลักจะถูกห้าม (Disallow) ไว้ก็ตาม คำสั่งนี้มีประโยชน์เมื่อคุณห้ามทั้งโฟลเดอร์ แต่มีบางไฟล์ภายในโฟลเดอร์นั้นที่ยังต้องการให้ Googlebot เข้าถึงได้ การใช้ Allow ร่วมกับ Disallow ช่วยให้สามารถสร้างกฎการควบคุมการสแกนที่ซับซ้อนและเฉพาะมากขึ้น
4. Sitemap
ตัวอย่าง Code
Sitemap: https://www.example.com/sitemap.xml
Sitemap เป็นคำสั่งพิเศษที่ไม่เกี่ยวกับการควบคุมการสแกนโดยตรง แต่ทำหน้าที่ ‘แจ้งตำแหน่ง’ ของ Sitemap ให้บอต การระบุตำแหน่ง Sitemap ไว้ในไฟล์ Robots.txt เป็นแนวทางปฏิบัติที่ดีที่สุด เนื่องจากช่วยให้เครื่องมือค้นหาค้นพบหน้าเว็บทั้งหมดที่ต้องการ ให้จัดทำดัชนีได้ง่ายๆ และมีประสิทธิภาพ

การเขียนคำสั่ง Script ในไฟล์ Robots.txt
การเขียนคำสั่ง Script ในไฟล์ Robots.txt คือการกำหนดกฎหรือข้อบังคับให้กับบอตของ Search Engine ว่าสามารถเข้าหรือไม่เข้าไปเก็บข้อมูลหน้าเว็บไหน โฟลเดอร์ไหน หรือไฟล์ชนิดไหนได้บ้าง เพื่อควบคุมการจัดทำดัชนีและเพิ่มประสิทธิภาพ SEO ของเว็บไซต์ให้ตรงตามที่ต้องการ
กฎหรือคำสั่ง (Rules) พร้อมตัวอย่างในไฟล์ Robots.txt มีดังนี้
- ไม่อนุญาตให้ Search Engine ตัวใดตัวหนึ่งหรือทั้งหมด เข้ามาเก็บข้อมูลทั้งเว็บไซต์
User-agent: *
Disallow: /
- ไม่อนุญาตให้เก็บข้อมูลหน้าเพจและไดเรกทอรีที่ระบุ เช่น โฟลเดอร์ Calendar หรือหน้าเพจเฉพาะ
User-agent: *
Disallow: /calendar/
Disallow: /junk/
Disallow: /books/fiction/contemporary/
- อนุญาตให้ Search Engine เพียงบางตัว เช่น Googlebot-news เข้าถึงเว็บไซต์ และบล็อกตัวอื่นทั้งหมดไม่ให้เข้ามาเก็บข้อมูล
User-agent: Googlebot-news
Allow: /
User-agent: *
Disallow: /
- อนุญาตให้ Search Engine ทุกตัว ยกเว้นตัวหนึ่งที่ไม่อนุญาต เช่น Unnecessarybot
User-agent: Unnecessarybot
Disallow: /
User-agent: *
Allow: /
- ไม่อนุญาตเข้าถึงไฟล์หรือหน้าเพจเฉพาะ เช่น /useless_file.html
User-agent: *
Disallow: /useless_file.html
Disallow: /junk/other_useless_file.html
- อนุญาตเฉพาะบางโฟลเดอร์หรือหน้า เช่น บล็อกทั้งเว็บไซต์ ยกเว้น /public/
User-agent: *
Disallow: /
Allow: /public/
- บล็อกไม่ให้แสดงรูปภาพบางไฟล์บน Google Image เช่น /images/dogs.jpg
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
- บล็อกรูปภาพทั้งหมดในเว็บไซต์ ไม่ให้แสดงบน Google Image
User-agent: Googlebot-Image
Disallow: /
- ไม่อนุญาตให้บอตเก็บข้อมูลไฟล์บางประเภท เช่น .gif
User-agent: Googlebot
Disallow: /*.gif$
- บล็อก Search Engine ทุกตัว ยกเว้น Mediapartners-Google (ใช้ใน Google Ads)
User-agent: *
Disallow: /
User-agent: Mediapartners-Google
Allow: /
- ไม่อนุญาตให้เก็บข้อมูล URL ที่มีนามสกุลหรือคำที่ระบุ เช่น .xls
User-agent: Googlebot
Disallow: /*.xls$

Robots.txt สำคัญยังไงต่อการทำ SEO?
หลายคนอาจมองว่าไฟล์เล็กๆ อย่าง Robots.txt ไม่น่าจะมีผลต่ออันดับเว็บไซต์เท่าไร แต่ในความเป็นจริงกลับเป็นเครื่องมือสำคัญที่ช่วยให้ Search Engine จัดการข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น การตั้งค่าที่ถูกต้องจะช่วยให้บอตเข้าถึงหน้าเว็บที่มีคุณค่า และหลีกเลี่ยงหน้าที่ไม่จำเป็น ช่วยให้เว็บไซต์ถูกประมวลผลเร็วขึ้นและมีโอกาสติดอันดับที่ดีกว่าเดิม
ควบคุมงบการเก็บข้อมูล (Crawl Budget)
ไฟล์ Robots.txt มีบทบาทสำคัญในการจัดการ ‘Crawl Budget’ หรือปริมาณการเข้ามาเก็บข้อมูลของบอตในแต่ละเว็บไซต์ การกำหนดให้บอตข้ามหน้าที่ไม่จำเป็น เช่น หน้าทดลองหรือหน้าซ้ำ จะช่วยให้บอตใช้ทรัพยากรเก็บข้อมูลเฉพาะหน้าที่สำคัญต่อ SEO มากกว่า ผลลัพธ์คือเว็บไซต์โหลดเร็วขึ้น มีการจัดทำดัชนีอย่างมีคุณภาพ และเพิ่มโอกาสให้หน้าหลักๆ ปรากฏบนผลการค้นหามากขึ้น
ป้องกันการแสดงหน้าที่ไม่ต้องการในผลค้นหา
อีกหนึ่งหน้าที่สำคัญของ Robots.txt คือการช่วยป้องกันไม่ให้หน้าที่ไม่ต้องการ เช่น หน้าทดลอง หน้าหลังบ้าน หรือหน้าที่มีข้อมูลซ้ำ ปรากฏในผลการค้นหา การใช้คำสั่ง Disallow จะช่วยบอกบอตว่า “ไม่ต้องเข้ามาเก็บข้อมูลในหน้านี้” ช่วยลดปัญหาเนื้อหาซ้ำ (Duplicate Content) และทำให้ Search Engine โฟกัสเฉพาะหน้าที่มีคุณค่าต่อการจัดอันดับจริงๆ ผลลัพธ์คือโครงสร้างเว็บไซต์สะอาดขึ้น และคุณภาพของ SEO โดยรวมก็ดีขึ้นตามไปด้วย
ช่วยจัดการเนื้อหาซ้ำ (Duplicate Content)
ปัญหาเนื้อหาซ้ำถือเป็นหนึ่งในสาเหตุที่ทำให้เว็บไซต์เสียอันดับ SEO โดยไม่รู้ตัว ซึ่ง Robots.txt เข้ามาช่วยได้ตรงจุด เพราะเราสามารถใช้คำสั่ง Disallow เพื่อบอกบอตไม่ให้เข้าไปเก็บข้อมูลในหน้าที่มีเนื้อหาซ้ำหรือคล้ายกับหน้าหลัก เช่น หน้าพารามิเตอร์หรือหน้าฟิลเตอร์สินค้า เมื่อบอตไม่เข้าไปเก็บข้อมูลเหล่านี้ ก็ช่วยลดความซ้ำซ้อนในดัชนีของ Google ทำให้บอตโฟกัสเฉพาะหน้าที่มีเนื้อหาหลักและมีคุณค่าจริงๆ
ป้องกันบอตไม่ให้ทำ Index ไฟล์บนเว็บไซต์
บางครั้งเว็บไซต์มีไฟล์ภายใน เช่น เอกสาร PDF รูปภาพ สคริปต์ หรือไฟล์ระบบ ที่ไม่จำเป็นต้องปรากฏในผลการค้นหา การใช้คำสั่งใน Robots.txt เช่น Disallow: /*.pdf$ หรือ Disallow: /scripts/ ช่วยบอกบอตว่า “ไม่ต้องจัดทำดัชนีไฟล์เหล่านี้” ซึ่งมีประโยชน์มากต่อ SEO เพราะช่วยป้องกันไม่ให้ Google แสดงไฟล์ที่ไม่เกี่ยวข้องกับเนื้อหาหลัก ลดความสับสนของบอต และช่วยให้พลังการจัดทำดัชนีถูกใช้กับหน้าที่สำคัญจริงๆ ของเว็บไซต์แทน

ข้อควรระวังในการใช้ Robots.txt
แม้ไฟล์ Robots.txt จะช่วยควบคุมบอตและจัดระเบียบเว็บไซต์ได้ดี แต่หากใช้อย่างไม่ระมัดระวัง อาจส่งผลเสียต่อ SEO หรือทำให้หน้าสำคัญหายจากผลการค้นหาได้ การเข้าใจข้อควรระวังและตรวจสอบก่อนใช้งานจึงเป็นสิ่งสำคัญ
อย่าใช้เพื่อซ่อนข้อมูลสำคัญ
Robots.txt ไม่ได้ออกแบบมาเพื่อซ่อนความลับหรือข้อมูลสำคัญ เช่น ไฟล์ลูกค้า ข้อมูลหลังบ้าน หรือไฟล์ระบบ เพราะถึงแม้จะใส่คำสั่ง Disallow: เพื่อห้ามบอตเข้าถึง แต่คนทั่วไปยังสามารถเห็นรายชื่อโฟลเดอร์หรือไฟล์ที่ถูกบล็อกได้จากไฟล์ Robots.txt เอง ซึ่งอาจกลายเป็นช่องทางให้ผู้ไม่หวังดีรู้ว่าข้อมูลสำคัญอยู่ที่ไหน ทางที่ถูกคือควรใช้มาตรการความปลอดภัยอื่นๆ เช่น การตั้งรหัสผ่าน หรือการจำกัดสิทธิ์การเข้าถึงผ่านเซิร์ฟเวอร์แทน
ระวังการบล็อกหน้าสำคัญโดยไม่ตั้งใจ
หนึ่งในความผิดพลาดที่พบบ่อยในการใช้ Robots.txt คือการใส่คำสั่ง Disallow มากเกินไป หรือกำหนดเส้นทางผิด จนเผลอบล็อกหน้าสำคัญที่ควรให้ Google เข้าถึง เช่น หน้าแรก หน้า Product หรือหน้าบทความหลัก เมื่อบอตไม่สามารถเข้าถึงหน้าเหล่านี้ได้ ก็จะไม่ถูกจัดทำดัชนี ส่งผลให้เว็บไซต์หายจากผลการค้นหาและกระทบอันดับ SEO โดยตรง ดังนั้นก่อนบันทึกไฟล์ Robots.txt ควรตรวจสอบคำสั่งทุกครั้ง หรือทดสอบผ่านเครื่องมืออย่าง Google Search Console เพื่อให้มั่นใจว่าหน้าสำคัญยังถูกเข้าถึงได้ตามปกติ
ใช้ร่วมกับ Meta Robots
อีกเรื่องที่ควรระวังคือการใช้ Robots.txt ร่วมกับ Meta Robots Tag ภายในหน้าเว็บไซต์ เพราะทั้งสองอย่างมีหน้าที่ควบคุมการเข้าถึงและการจัดทำดัชนีของบอตเช่นเดียวกัน แต่ทำงานคนละระดับ หากตั้งค่าซ้ำซ้อนหรือขัดกัน เช่น ใช้ Robots.txt บล็อกหน้าไว้ แต่ในหน้าเดียวกันกลับใส่ Meta Robots ว่า ‘index’ จะทำให้บอตสับสน และอาจส่งผลให้บางหน้าหายจากผลการค้นหาโดยไม่ตั้งใจ ดังนั้นก่อนใช้ควรตรวจสอบให้แน่ใจว่าทั้งสองส่วนทำงานไปในทิศทางเดียวกัน เพื่อป้องกันปัญหาการจัดทำดัชนีผิดพลาดที่อาจกระทบต่อ SEO
ทดสอบก่อนใช้งานจริง
ก่อนนำไฟล์ Robots.txt ไปใช้จริงบนเว็บไซต์ ควรทดสอบให้แน่ใจก่อนเสมอว่าคำสั่งทั้งหมดทำงานถูกต้อง เพราะแค่พิมพ์ผิดบรรทัดเดียว อาจทำให้บอตของ Google ถูกบล็อกจากหน้าเว็บไซต์สำคัญโดยไม่ตั้งใจ การทดสอบสามารถทำได้ง่ายๆ ผ่านเครื่องมือ Robots.txt Tester ใน Google Search Console ซึ่งจะแสดงผลทันทีว่าบอตสามารถเข้าถึงหน้าไหนได้หรือไม่ได้ การตรวจสอบล่วงหน้าทำให้ไม่เสี่ยง ‘หายจากผลการค้นหา’ และทำให้มั่นใจว่าเว็บไซต์จะยังทำงานสอดคล้องกับกลยุทธ์ SEO อย่างปลอดภัย

วิธีสร้างและใช้งาน Robots.txt ง่ายๆ สำหรับมือใหม่
สำหรับมือใหม่ การสร้างไฟล์ Robots.txt อาจฟังดูซับซ้อน แต่จริงๆ แล้วทำได้ไม่ยาก หากทำตามขั้นตอนทีละขั้นและตรวจสอบอย่างรอบคอบ ไฟล์นี้ช่วยให้คุณควบคุมบอต จัดลำดับความสำคัญของหน้าเว็บไซต์ และปกป้องข้อมูลบางส่วนได้เหมาะสม
ขั้นตอนการสร้าง (วางในเว็บไซต์ด้วยตัวเอง)
- เปิดโปรแกรมแก้ไขข้อความ เช่น Notepad หรือ TextEdit
- สร้างไฟล์ใหม่และตั้งชื่อว่า robots.txt
- เขียนคำสั่งพื้นฐาน เช่น
User-agent: *
Disallow: /private/
Allow: /public/
Sitemap: https://www.example.com/sitemap.xml
- บันทึกไฟล์และตรวจสอบให้แน่ใจว่าเป็น .txt จริงๆ ไม่ใช่ .txt.rtf
- อัปโหลดไฟล์ไปที่โฟลเดอร์รากของเว็บไซต์ผ่าน FTP หรือ File Manager
ขั้นตอนการสร้าง (ใช้ปลั๊กอิน)
- ติดตั้งปลั๊กอิน SEO ที่รองรับการสร้าง Robots.txt เช่น Yoast SEO หรือ All in One SEO
- เข้าไปที่เมนูการตั้งค่า SEO > Tools หรือ File Editor
- เลือกสร้างหรือแก้ไขไฟล์ Robots.txt ผ่านอินเทอร์เฟซของปลั๊กอิน
- กรอกคำสั่งพื้นฐาน เช่น Disallow, Allow และ Sitemap ตามที่ต้องการ
- บันทึกและตรวจสอบว่าปลั๊กอินอัปเดตไฟล์ใน Root Directory เรียบร้อย
ขั้นตอนการตรวจสอบไฟล์
- เปิดเว็บเบราว์เซอร์และพิมพ์ https://www.example.com/robots.txt เพื่อดูไฟล์จริง
- ตรวจสอบว่าคำสั่งทั้งหมดถูกต้องและตรงกับที่ตั้งใจ
- ใช้ Google Search Console > Robots.txt Tester เพื่อตรวจสอบว่าบอตสามารถเข้าถึงหรือถูกบล็อกตามที่ต้องการ
- แก้ไขข้อผิดพลาดหากพบหน้าที่สำคัญถูกบล็อกโดยไม่ตั้งใจ
- ทดสอบซ้ำจนมั่นใจว่าไฟล์ทำงานได้ตามแผน

จะเกิดอะไรขึ้น? ถ้าเว็บไซต์ไม่มีไฟล์ Robots.txt
หลายคนอาจไม่รู้ว่า ถ้าเว็บไซต์ไม่มีไฟล์ Robots.txt บอตของ Search Engine จะเข้ามาเก็บข้อมูลโดยไม่มีข้อจำกัด ซึ่งแม้จะฟังดูเหมือนดีที่ทุกหน้าจะถูกเก็บ แต่จริงๆ แล้วอาจสร้างปัญหาได้ หากมีหน้าเว็บไซต์ที่ไม่ต้องการให้บอตเข้าถึง หรือมีเนื้อหาซ้ำมากมาย
บอตจะเก็บข้อมูลทุกหน้าเท่าที่เข้าได้
หากเว็บไซต์ไม่มีไฟล์ Robots.txt หรือไฟล์นั้นว่างเปล่า Web Crawlers จะถือว่าได้รับอนุญาตให้สแกนทุกหน้า และทุกส่วนที่สามารถเข้าถึงได้ผ่านลิงก์บนเว็บไซต์ หมายความว่าทุก URL ที่ค้นพบจะถูกจัดอยู่ในคิวสำหรับการสแกนโดยไม่มีการยกเว้น บอตจะพยายามเข้าถึงหน้าต่างๆ เช่น หน้าเข้าสู่ระบบ หน้าสำหรับผู้ดูแลระบบ หรือหน้าตะกร้าสินค้า ที่โดยปกติแล้วไม่จำเป็นต้องสแกน
อาจสิ้นเปลือง Crawl Budget
เว็บไซต์ขนาดใหญ่มี Crawl Budget ที่จำกัด ซึ่งเป็นจำนวนหน้าเว็บไซต์ที่บอตจะสแกนภายในช่วงเวลาหนึ่ง เมื่อไม่มี Robots.txt บอตจะใช้จ่ายงบประมาณนี้ไปกับการสแกนหน้าเว็บไซต์ที่ไม่มีความสำคัญ เช่น หน้าสำหรับผู้ดูแลระบบหรือ URL ที่ซ้ำซ้อน เป็นผลให้หน้าเว็บไซต์หลักและหน้าสำคัญอาจถูกสแกนและจัดทำดัชนีช้าลง หรือไม่ครบถ้วนนั่นเอง
เนื้อหาที่ไม่ต้องการอาจโผล่ในผลค้นหา
หากไม่มีคำสั่ง Disallow ที่เหมาะสม บอตจะสแกนและจัดทำดัชนีทุกเนื้อหาที่เข้าถึงได้ ซึ่งอาจรวมถึงหน้าเว็บไซต์ที่ตั้งใจจะซ่อนจากสาธารณะ เช่น หน้าทดสอบ ไฟล์เอกสารภายใน หรือหน้าที่มีเนื้อหาซ้ำซ้อน ทำให้ผลการค้นหาของเว็บไซต์แสดงเนื้อหาที่ไม่เกี่ยวข้องหรือดูไม่น่าเชื่อถือสำหรับผู้ใช้งาน
ไม่กระทบอันดับโดยตรง แต่กระทบการจัดการ SEO ทางอ้อม
แม้การไม่มีไฟล์ Robots.txt จะไม่ทำให้เว็บไซต์เสียอันดับทันทีใน Google แต่กลับส่งผลต่อการจัดการ SEO ชัดเจน เพราะบอตต้องเสียเวลาค้นหาหน้าทั้งหมด รวมถึงหน้าที่ไม่สำคัญ ทำให้ Crawl Budget ถูกใช้ไม่คุ้ม และเพิ่มความเสี่ยงที่เนื้อหาจะซ้ำ หรือหน้าที่ไม่ต้องการปรากฏในผลการค้นหา เมื่อบอตไม่สามารถโฟกัสไปที่หน้าสำคัญได้เต็มที่ การปรับปรุง SEO และการติดอันดับในระยะยาวก็อาจทำได้ช้าลง
บอตบางประเภทอาจทำให้เซิร์ฟเวอร์ทำงานหนักขึ้น
เมื่อเว็บไซต์ไม่มีไฟล์ Robots.txt บอตทุกตัวจะเข้ามาเก็บข้อมูลทุกหน้าเท่าที่เข้าถึงได้ รวมถึงบอตที่ไม่ได้มีจุดประสงค์ทาง SEO เช่น บอตเก็บข้อมูลหรือบอตสแปม ส่งผลให้เซิร์ฟเวอร์ต้องประมวลผลคำขอจำนวนมากพร้อมกัน ซึ่งอาจทำให้เว็บไซต์โหลดช้าลงหรือเกิด Downtime ชั่วคราว แม้จะไม่ได้กระทบอันดับโดยตรง แต่ประสบการณ์ผู้ใช้งานแย่ลงและ Google อาจสังเกตความช้าของเว็บไซต์ ซึ่งมีผลต่อการจัดอันดับทางอ้อม
สรุป
Robots.txt เป็นไฟล์ข้อความเล็กๆ ที่อยู่ในโฟลเดอร์รากของเว็บไซต์ มีบทบาทสำคัญในการควบคุมบอตของ Search Engine ว่าควรหรือไม่ควรเข้าถึงหน้าเว็บไซต์หรือโฟลเดอร์ใด ช่วยจัดการ Crawl Budget ป้องกันเนื้อหาซ้ำ และลดความเสี่ยงที่หน้าที่ไม่สำคัญจะโผล่บนผลการค้นหา การตั้งค่าอย่างระมัดระวังและตรวจสอบไฟล์ก่อนใช้งานจึงสำคัญต่อการทำ SEO ที่มีประสิทธิภาพ
หากคุณต้องการให้เว็บไซต์ถูกจัดทำดัชนีอย่างถูกต้องและเต็มประสิทธิภาพ ทีม Minimice Group รับทำ SEO ครบวงจร ทั้งการวิเคราะห์เว็บไซต์ ปรับโครงสร้างเนื้อหา การจัดการ Robots.txt และการทำ Technical SEO เพื่อให้เว็บไซต์ของคุณติดอันดับและเข้าถึงกลุ่มเป้าหมายได้อย่างมีประสิทธิภาพ
คำถามที่พบบ่อยเกี่ยวกับ Robots.txt (FAQ)
ไฟล์ TXT ในโทรศัพท์ คืออะไร?
ไฟล์ TXT เป็นไฟล์ข้อความธรรมดาที่เก็บข้อมูลตัวอักษรล้วนๆ ไม่มีฟอร์แมตหรือรูปแบบพิเศษ ใช้จดบันทึก สร้างโน้ต หรือเก็บข้อมูลสั้นๆ บนโทรศัพท์ได้ง่ายและเปิดอ่านได้ทุกอุปกรณ์
Web Robot คืออะไร?
Web Robot หรือบอตเว็บ เป็นโปรแกรมอัตโนมัติที่เข้ามาเก็บข้อมูลบนเว็บไซต์ เช่น Googlebot เพื่อช่วย Search Engine ทำดัชนีเว็บไซต์ ทำให้หน้าต่างๆ ปรากฏในผลการค้นหา
โปรแกรมบอตคืออะไร?
โปรแกรมบอตคือซอฟต์แวร์ที่ทำงานอัตโนมัติแทนคน เช่น ส่งข้อความ ดาวน์โหลดข้อมูล หรือเก็บข้อมูลบนเว็บไซต์ บางบอตถูกใช้เพื่อ SEO หรือวิเคราะห์ข้อมูล ในขณะที่บางบอตอาจสร้างสแปมหรือทำงานแบบไม่พึงประสงค์

