



Key Takeaway
- GoogleBot เป็น Web Crawler ของ Google ที่ทำหน้าที่สำรวจและรวบรวมข้อมูลจากเว็บไซต์ทั่วโลก โดยติดตามลิงก์จากหน้าเว็บหนึ่งไปยังอีกหน้าเว็บหนึ่งเพื่อนำข้อมูลมาใช้ในการแสดงผลการค้นหาบน Google
- หลักการทำงานของ GoogleBot คือการสำรวจ รวบรวม วิเคราะห์ และประมวลผลข้อมูล เพื่อจัดอันดับเว็บไซต์ ทำให้ผู้ใช้สามารถเข้าถึงข้อมูลที่ถูกต้องและตรงกับความต้องการได้มากที่สุด
- เทคนิคการปรับแต่งเว็บไซต์ให้เหมาะกับ GoogleBot คือการสร้าง Sitemap ตั้งค่า Robots.txt ให้เหมาะสม ใช้โครงสร้าง Heading Tags ให้เป็นระเบียบ เขียนเนื้อหาตามหลัก SEO และแก้ไข Error Pages อย่างสม่ำเสมอ เพื่อให้บอตสามารถรวบรวมข้อมูลได้ง่ายและมีประสิทธิภาพสูงสุด
GoogleBot เป็นกุญแจสำคัญในการทำ SEO ที่หลายคนอาจไม่เคยรู้มาก่อนว่ามันคือซอฟต์แวร์ของ Google ที่ทำหน้าที่รวบรวมข้อมูลจากเว็บไซต์ต่างๆ เพื่อจัดทำดัชนีและกำหนดอันดับในการค้นหา โดยหากเว็บไซต์ได้รับการประมวลผลอย่างถูกต้อง โอกาสในการติดอันดับต้นๆ บน Google ก็จะสูงขึ้นด้วยเช่นกัน
ในบทความนี้จะพาทุกคนไปทำความรู้จักกับ GoogleBot แบบเจาะลึกว่ามันคืออะไร ทำงานอย่างไร และมีบทบาทสำคัญอย่างไรต่อการจัดอันดับเว็บไซต์บน Google นอกจากนี้ยังมีเทคนิคการปรับแต่งเว็บไซต์ให้เป็นมิตรกับ GoogleBot เพื่อเพิ่มโอกาสให้เว็บของคุณติดอันดับการค้นหาได้ง่ายขึ้นมาแนะนำเพิ่มเติมอีกด้วย
GoogleBot คืออะไร ทำไมถึงสำคัญต่อการจัดอันดับบนหน้าค้นหา
GoogleBot คือซอฟต์แวร์รวบรวมข้อมูล (Web Crawler) ของ Google ที่ใช้สำหรับสแกนและเก็บข้อมูลจากเว็บไซต์ต่างๆ บนอินเทอร์เน็ต โดยมี Bot ทำหน้าที่เป็นนักสำรวจในการเข้าไปอ่านเนื้อหา รูปภาพ ลิงก์ และองค์ประกอบของเว็บไซต์ต่างๆ เพื่อนำไปประมวลผลบนระบบของ Google จากนั้นข้อมูลที่ได้จะถูกนำไปวิเคราะห์และใช้ในการจัดอันดับบนหน้าผลการค้นหา (SERPs)
ซึ่งมีความสำคัญอย่างยิ่งสำหรับการทำ SEO เพราะหากเว็บไซต์ได้รับการประมวลผลอย่างถูกต้อง เว็บก็จะมีโอกาสติดอันดับที่ดีขึ้นบน Google ขณะเดียวกันหาก GoogleBot ไม่สามารถเข้าถึงเว็บไซต์หรืออ่านข้อมูลได้ไม่ครบถ้วน อาจทำให้หน้าเว็บไม่ปรากฏบนผลการค้นหาในหน้า Google ได้เช่นกัน

หลักการทำงานของ GoogleBot
การทำความเข้าใจหลักการทำงาน GoogleBot คือสิ่งสำคัญที่จะช่วยให้เราสามารถปรับแต่งเว็บไซต์ได้อย่างเหมาะสม เพื่อเพิ่มโอกาสในการติดอันดับที่ดีขึ้นได้ โดย GoogleBot มีหลักการทำงาน 4 ขั้นตอน ดังนี้
หาข้อมูล – Crawling
ในขั้นตอนแรก GoogleBot จะเข้าไปสำรวจเว็บไซต์โดยเริ่มจาก URL ที่มีอยู่ในฐานข้อมูล จากนั้นจะติดตามลิงก์ภายใน (Internal Links) ที่เชื่อมไปยังหน้าอื่นภายในเว็บไซต์ หรือ ลิงก์ภายนอก (Backlinks) ที่มาจากเว็บไซต์อื่นเพื่อตรวจสอบคุณภาพและความเชื่อมโยงของเนื้อหา โดย GoogleBot จะอ้างอิง Robots.txt เพื่อตรวจสอบว่ามีหน้าหรือไฟล์ใดที่ได้รับอนุญาตให้เข้าถึง และใช้ Sitemap เป็นแนวทางเพื่อค้นหาหน้าสำคัญของเว็บไซต์
หากเว็บไซต์โหลดได้เร็วและโครงสร้างลิงก์ดี GoogleBot ก็จะสามารถสแกนข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น แต่หาก Bot พบว่าลิงก์ที่เชื่อมโยงไปไม่มีความเกี่ยวข้องหรือไม่สามารถเข้าถึงได้ Bot จะทำการประเมินในทันทีว่าเว็บไซต์ขาดความน่าเชื่อถือ ซึ่งส่งผลโดยตรงต่ออันดับการค้นหาบน Google
อ่านข้อมูล – Rendering
Rendering คือกระบวนการที่ GoogleBot อ่านและประมวลผลหน้าเว็บไซต์ เพื่อทำความเข้าใจเนื้อหาและโครงสร้าง โดยจะดาวน์โหลด HTML, CSS, JavaScript และไฟล์ที่เกี่ยวข้องเพื่อตรวจสอบว่าองค์ประกอบต่างๆ เช่น ข้อความ รูปภาพ เมนู และปุ่มต่างๆ แสดงผลถูกต้องหรือไม่ หากเว็บไซต์ใช้ JavaScript มากเกินไป หรือโหลดเนื้อหาแบบ Lazy Loading อาจทำให้ GoogleBot อ่านข้อมูลได้ไม่ครบและส่งผลต่อการจัดอันดับบน Google ได้เช่นกัน
วิเคราะห์ข้อมูล – Indexing
หลังจากที่ GoogleBot อ่านข้อมูลเรียบร้อยแล้ว จะทำการวิเคราะห์และจัดเก็บข้อมูลเว็บไซต์ลงใน Google Index ซึ่งเป็นฐานข้อมูลหลักของ Google ที่ใช้สำหรับแสดงผลการค้นหา โดยกระบวนการนี้ถือเป็นขั้นตอนสำคัญในการประเมินคุณภาพของเว็บไซต์เพื่อพิจารณาว่าเว็บมีคุณค่าต่อผู้ใช้มากเพียงใดก่อนเข้าสู่การจัดอันดับ
จัดอันดับข้อมูล – Ranking
Ranking คือกระบวนการจัดอันดับเว็บไซต์บนหน้าผลการค้นหาของ Google โดยใช้อัลกอริทึมวิเคราะห์และประเมินคุณภาพของเว็บไซต์ที่ถูกจัดเก็บไว้ใน Google Index ซึ่งปัจจัยที่มีผลต่อการจัดอันมีหลายประการ ได้แก่ ความเกี่ยวข้องของเนื้อหา คุณภาพของข้อมูล ประสบการณ์ของผู้ใช้ ความเร็วของเว็บไซต์ รวมถึง Internal Links และ Backlinks
หากเว็บไซต์มีเนื้อหาที่ตรงกับคำค้นหาและให้ประสบการณ์ที่ดีแก่ผู้ใช้งาน ก็จะมีโอกาสได้รับการจัดอันดับที่สูงขึ้น ส่งผลให้เว็บไซต์มีการเข้าชมมากขึ้น และเพิ่มโอกาสทางธุรกิจได้มากยิ่งขึ้นอีกด้วย
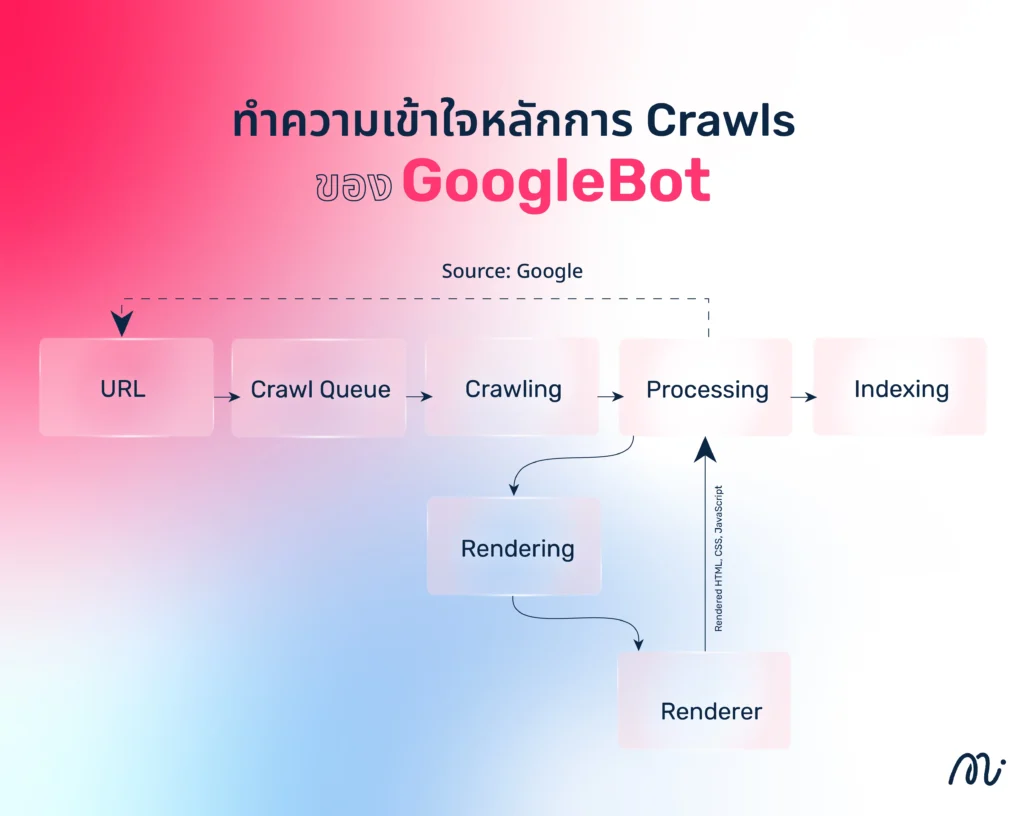
ทำความเข้าใจหลักการ Crawls ของ GoogleBot
การทำงานของ Crawl ของ GoogleBot สามารถแบ่งได้ตามขั้นตอนดังต่อไปนี้
1. รับรายการ URL
GoogleBot จะได้รับรายการ URL จากแหล่งต่างๆ เช่น แผนผังเว็บไซต์ (Sitemap) ลิงก์จากเว็บไซต์อื่น (Backlinks) หรือการส่ง URL ผ่าน Google Search Console เพื่อให้ระบบสามารถค้นพบหน้าเว็บใหม่หรืออัปเดตข้อมูลที่มีอยู่แล้วให้เป็นปัจจุบัน
2. การเข้าสู่คิวการรวบรวมข้อมูล (Crawl Queue)
เมื่อ GoogleBot ได้รับ URL ระบบจะนำไปจัดลำดับความสำคัญใน Crawl Queue เพื่อกำหนดว่าควรจะเข้าไปเก็บข้อมูลหน้าเว็บใดก่อน โดยพิจารณาจากคุณภาพของเว็บไซต์ ความถี่ในการอัปเดต ความเร็วขอ เซิร์ฟเวอร์ และความน่าเชื่อถือของแหล่งที่มา ซึ่งหน้าเว็บที่มีความสำคัญสูงจะถูกเข้าถึงก่อนเป็นอันดับต้นๆ
3. การรวบรวมข้อมูลโดย GoogleBot (Crawling)
จากนั้น GoogleBot จะเข้าไปที่เว็บไซต์ตาม URL ในคิว เพื่อรวบรวมข้อมูลที่เกี่ยวข้อง เช่น เนื้อหาบนหน้าเว็บ (Text) รูปภาพ ลิงก์ภายใน และข้อมูลโครงสร้าง (Structured Data) หากหน้าเว็บมีการเปลี่ยนแปลงหรืออัปเดต ระบบจะทำการ Crawl ใหม่อีกครั้งตามรอบที่กำหนด
4. การประมวลผลข้อมูล (Processing & Rendering)
หลังจากรวบรวมข้อมูลแล้ว Google จะประมวลผลเนื้อหาโดยตรวจสอบและวิเคราะห์องค์ประกอบต่างๆ เช่น ข้อความ โคด HTML และลิงก์ สำหรับหน้าเว็บที่ใช้ JavaScript หรือมีโครงสร้างซับซ้อน ระบบจะทำการเรนเดอร์ (Rendering) โดยโหลด HTML, CSS และ JavaScript เพื่อให้แสดงผลได้เช่นเดียวกับที่ผู้ใช้มองเห็น
5. การบันทึกข้อมูลในระบบค้นหา (Indexing)
เมื่อ Google ประมวลผลหน้าเว็บเสร็จแล้วข้อมูลจะถูกบันทึกลงในระบบค้นหา เพื่อนำไปใช้แสดงผลเมื่อมีผู้ค้นหา จากนั้นระบบจะวิเคราะห์คีย์เวิร์ด ตรวจสอบความเกี่ยวข้องของเนื้อหา และประเมินคุณภาพของเว็บไซต์ก่อนนำไปจัดอันดับให้เหมาะสมกับผลลัพธ์ในการค้นหาต่อไป

ตัวช่วยควบคุมการทำงานของ GoogleBot
แม้ว่า GoogleBot จะทำงานโดยอัตโนมัติ แต่เจ้าของเว็บไซต์สามารถกำหนดและควบคุมการทำงานของ GoogleBot ได้ เพื่อป้องกันไม่ให้บอตเข้าถึงบางส่วนของเว็บไซต์ โดยใช้ตัวช่วยดังต่อไปนี้
ตัวช่วยควบคุมการ Crawling
เจ้าของเว็บไซต์สามารถกำหนดว่าหน้าเว็บใดต้องการให้ GoogleBot เข้าถึงหรือไม่เข้าถึง (Crawling) เพื่อป้องกันการโหลดข้อมูลที่ไม่จำเป็นและลดภาระเซิร์ฟเวอร์ โดยใช้เครื่องมือต่อไปนี้
- Robots.txt เป็นไฟล์ที่ใช้กำหนดว่า GoogleBot สามารถหรือไม่สามารถเข้าถึงไดเรกทอรีหรือหน้าเว็บใดได้ โดยการเพิ่มคำสั่ง Disallow เพื่อบล็อกหน้าเว็บจากการถูกรวบรวมข้อมูล
- Meta Robots Tag เป็นคำสั่งที่อยู่ในโคด HTML ของแต่ละหน้าเว็บ ซึ่งช่วยกำหนดให้ GoogleBot เก็บข้อมูล (Index) หรือไม่เก็บข้อมูล Noindex) รวมถึงติดตามลิงก์ (Follow) หรือไม่ติดตามลิงก์ (Nofollow) ได้
- Google Search Console (GSC) ใช้กำหนด Crawl Rate เพื่อควบคุมความถี่ที่ GoogleBot เข้ามาเก็บข้อมูล ซึ่งสามารถใช้ Removals Tool เพื่อลบ URL ออกจากผลการค้นหาชั่วคราวได้
- Canonical Tag เป็นคำสั่งที่ ใช้บอก Google ว่าหน้าไหนเป็นเวอร์ชันหลัก เพื่อลดปัญหาการ Duplicate Content ช่วยให้ GoogleBot ไม่ต้อง Crawl หน้าเว็บที่มีเนื้อหาซ้ำกันหลายหน้า
- Sitemap XML เป็นการส่ง Sitemap ไปยัง Google Search Console เพื่อให้ GoogleBot รู้ว่าควร Crawl หน้าไหนก่อน ซึ่งสามารถกำหนด Priority และ Update Frequency เพื่อช่วยจัดลำดับความสำคัญได้
ตัวช่วยควบคุมการ Indexing
เจ้าของเว็บไซต์สามารถกำหนดได้ว่าหน้าเว็บใดควรหรือไม่ควรถูกบันทึกลงในระบบค้นหาของ Google (Indexing) โดยใช้เครื่องมือต่อไปนี้
- Meta robots tag เป็นการใช้คำสั่งในโคด HTML ของหน้าเว็บ เพื่อกำหนดให้ GoogleBot ไม่บันทึก (noindex) ข้อมูลของหน้าเว็บในระบบค้นหา
- Password Protection หรือ Restrict Access เป็นการป้องกันการเข้าถึงเว็บไซต์ด้วยรหัสผ่านหรือการจำกัดสิทธิ์การเข้าถึง เพื่อให้ GoogleBot ไม่สามารถ Crawl หรือ Index หน้าเว็บที่ถูกป้องกันด้วยวิธีนี้ได้
- X-Robots-Tag เป็น HTTP Header ที่ใช้ควบคุมการทำงานของ GoogleBot โดยกำหนดเงื่อนไขต่างๆ ได้ เช่น ไม่ให้บันทึกข้อมูล ไม่ให้ติดตามลิงก์ หรือไม่ให้แสดงเนื้อหาในผลการค้นหา ซึ่งสามารถใช้ได้กับไฟล์ทุกประเภท ไม่ว่าจะเป็น HTML PDF รูปภาพ วิดีโอ หรือไฟล์เอกสารอื่นๆ

เทคนิคการปรับแต่งเว็บไซต์ให้เหมาะกับ GoogleBot
ในยุคที่การค้นหาข้อมูลผ่าน Google เป็นช่องทางที่ได้รับความนิยมสูงในปัจจุบัน การทำให้เว็บไซต์เป็นมิตรกับ GoogleBot จึงเป็นสิ่งสำคัญ เพื่อให้เว็บไซต์อยู่ในอันดับต้นๆ ของผลการค้นหา ซึ่งเทคนิคการปรับแต่งเว็บไซต์ให้เหมาะกับ GoogleBot สามารถทำได้ดังแนวทางต่อไปนี้
1. สร้างแผนที่เว็บไซต์ (Site Map) ที่มีประสิทธิภาพ
Site Map คือไฟล์ที่รวมลิงก์ทุกหน้าบนเว็บไซต์ เพื่อช่วยให้ GoogleBot เข้าใจโครงสร้างเว็บและเข้าถึงหน้าเว็บต่างๆ ได้ง่ายขึ้น ซึ่งการสร้าง Site Map ที่ดีควรใช้ XML Sitemap และอัปโหลดไปยัง Google Search Console เพื่อให้ Google สามารถรวบรวมข้อมูลได้เร็วขึ้น ลดโอกาสที่หน้าเว็บสำคัญจะถูกมองข้ามและช่วยให้การจัดอันดับบนผลการค้นหามีประสิทธิภาพมากขึ้น
2. กำหนดวิธีให้ Google เข้ามาดูเว็บไซต์ด้วย Robot.txt
การใช้เครื่องมือ Robots.txt กำหนดการเข้าถึงหน้าเว็บต่างๆ จะช่วยให้ GoogleBot ทำงานได้อย่างมีประสิทธิภาพโดยไม่เปลืองทรัพยากรของเซิร์ฟเวอร์มากเกินไป ซึ่งสามารถตั้งค่าได้โดยเริ่มจากการสร้างไฟล์ Robots.txt และอัปโหลดไปยัง Root directory ของเว็บไซต์ จากนั้นใช้คำสั่ง Disallow เพื่อบล็อกหน้าเว็บที่ไม่ต้องการให้ GoogleBot เข้าไปและใช้คำสั่ง Allow เพื่อเปิดหน้าเว็บที่ต้องการให้เข้าถึง ซึ่งวิธีนี้ถือเป็นหนึ่งในเทคนิคสำคัญที่จะทำให้ Bot รวบรวมข้อมูลเว็บไซต์ได้ตรงจุด และทำให้เว็บไซต์ได้รับการจัดอันดับที่ดีขึ้นในการค้นหา
3. เขียนบทความคุณภาพสูง ถูกหลัก SEO
การเขียนบทความคุณภาพสูง คือบทความที่มีเนื้อหาเป็นประโยชน์ อ่านง่าย และตรงประเด็น โดยควรเลือกหัวข้อที่ตรงกับความต้องการของผู้ค้นหา ใช้คีย์เวิร์ดอย่างเป็นธรรมชาติ และในบทความควรมีการแทรก Internal Links หรือ External Links เพื่อช่วยให้ Googlebot เข้าใจความเชื่อมโยงของเนื้อหา และเพิ่มความน่าเชื่อถือของบทความได้มากยิ่งขึ้น ซึ่งการเขียนบทความที่ถูกหลัก SEO ไม่เพียงแต่จะช่วยให้เว็บไซต์มีอันดับที่ดีเท่านั้น แต่ยังช่วยให้เนื้อหาถูกค้นพบได้ง่าย และเพิ่มโอกาสในการเข้าถึงกลุ่มเป้าหมายได้มากยิ่งขึ้นอีกด้วย
4. จัดวาง Heading Tag ให้เป็นระเบียบ
Heading Tag เป็นโครงสร้างหัวข้อที่ช่วยจัดลำดับความสำคัญของเนื้อหาในหน้าเว็บ เพื่อทำให้ GoogleBot เข้าใจเนื้อหาได้ง่ายขึ้น โดยการจัดวาง Heading Tag ให้เป็นระเบียบ สามารถทำได้ดังนี้
- ใช้ H1 เพียงหนึ่งครั้ง เพื่อกำหนดหัวข้อหลัก
- ใช้ H2 สำหรับหัวข้อรอง
- ใช้ H3-H6 สำหรับหัวข้อย่อยตามลำดับ
- ควรจัดเรียงหัวข้อให้ตรงกับประเด็นของบทความ และใช้ คีย์เวิร์ดสำคัญ แทรกในบางส่วนของ Heading เสมอ
5. หมั่นแก้ไข Error Pages
Error Pages คือหน้าที่เกิดข้อผิดพลาด เช่น 404 Not Found, 500 Internal Server Error ซึ่งอาจเกิดจากลิงก์ที่ถูกลบหรือปัญหาทางเทคนิค ส่งผลให้ GoogleBot ไม่สามารถรวบรวมข้อมูลได้ครบถ้วนและอาจทำให้ผู้ใช้ได้รับประสบการณ์ที่ไม่ดีได้ โดยสามารถแก้ไขได้ ดังนี้
- ตรวจสอบหน้า Error ผ่าน Google Search Console โดยดูในรายงาน Crawled – Currently Not Indexed
- แก้ไขลิงก์ที่เสียหรือใช้ 301 Redirect เพื่อเปลี่ยนเส้นทางไปยังหน้าที่เกี่ยวข้อง
- ปรับแต่งหน้าข้อผิดพลาด 404 ให้นำผู้ใช้ไปยังเนื้อหาที่เกี่ยวข้อง แทนการแสดงหน้าเปล่า
- ตรวจสอบ Server Logs และ Error Reports เพื่อหาสาเหตุของปัญหาและแก้ไขอย่างรวดเร็ว
6. ตรวจสอบคุณภาพเว็บด้วย Google Search Console
Google Search Console เป็นเครื่องมือจาก Google ที่ช่วยให้เจ้าของเว็บไซต์ตรวจสอบประสิทธิภาพของเว็บไซต์ ปัญหาทางเทคนิค และการจัดอันดับในผลการค้นหาได้ ดังวิธีการต่อไปนี้
- เพิ่มเว็บไซต์ใน Google Search Console และยืนยันความเป็นเจ้าของ
- ตรวจสอบ Index Coverage เพื่อดูว่ามีหน้าเว็บใดที่ Google ไม่สามารถบันทึกข้อมูลได้
- ใช้ URL Inspection Tool เพื่อตรวจสอบว่า GoogleBot มองเห็นหน้าเว็บของคุณอย่างไรบ้าง
- ดูรายงาน Crawl Stats และ Core Web Vitals เพื่อตรวจสอบความเร็วและประสบการณ์ใช้งานของเว็บ
- หากพบข้อผิดพลาด เช่น Crawled – Currently Not Indexed สามารถแก้ไขและขอให้ GoogleBot รวบรวมข้อมูลใหม่ได้
ทั้งนี้ การตรวจสอบคุณภาพเว็บเป็นประจำจะช่วยให้เว็บไซต์ทำงานได้เต็มประสิทธิภาพสม่ำเสมอ ทำให้ GoogleBot สามารถรวบรวมข้อมูลได้อย่างถูกต้องและเพิ่มโอกาสให้เว็บไซต์สามารถติดอันดับต้นๆ ในการค้นหาได้

ขั้นตอนการบล็อก GoogleBot ไม่ให้เข้าชมเว็บไซต์
การบล็อก GoogleBot ไม่ให้เข้าชมเว็บไซต์คือการป้องกันไม่ให้บอตของ Google เข้าถึงและรวบรวมข้อมูลจากหน้าเว็บ ซึ่งสามารถทำได้ดังวิธีการต่อไปนี้
- สร้างไฟล์ Robots.txt เพื่อควบคุมการเข้าถึงหน้าเว็บไซต์
- กำหนดคำสั่งในไฟล์ Robots.txt โดยใช้คำสั่ง Disallow เพื่อบล็อกการเข้าถึงหน้าเว็บหรือไดเรกทอรีที่ต้องการ เช่น User-Agent: Googlebot Disallow: /Private/
- อัปโหลดไฟล์ Robots.txt ที่สร้างขึ้นไปวางไว้ที่ root directory ของเว็บไซต์ เพื่อให้บอตไม่สามารถเข้าถึงหน้าเว็บได้ตามคำสั่งที่กำหนด
- ตรวจสอบการตั้งค่า โดยใช้เครื่องมือ Robots.txt Tester ใน Google Search Console เพื่อตรวจสอบว่าไฟล์ Robots.txt ทำงานตามคำสั่งหรือไม่
อย่างไรก็ตาม การบล็อก GoogleBot อาจส่งผลกระทบต่อการแสดงผลของเว็บไซต์ในผลการค้นหาของ Google ในหลายด้าน ดังนี้
ผลกระทบเมื่อบล็อก GoogleBot
- Google ไม่สามารถเก็บข้อมูลหน้าเว็บ (Crawling ถูกจำกัด) หากบล็อก GoogleBot ด้วย Robots.txt หรือการตั้งค่าบนเซิร์ฟเวอร์ หน้าเว็บที่ถูกบล็อกจะไม่ถูกเก็บข้อมูล ส่งผลให้ Google ไม่สามารถอัปเดตเนื้อหาล่าสุดของเว็บไซต์ได้
- หน้าเว็บอาจไม่ปรากฏในผลการค้นหา (Indexing ถูกจำกัด) แม้ว่า Robots.txt จะบล็อกการ Crawl แต่ Google อาจยังคงแสดง URL ของหน้าเว็บที่ถูกบล็อก โดยไม่มีคำอธิบายหรือรายละเอียด ซึ่งอาจทำให้เว็บไซต์ดูไม่น่าเชื่อถือในสายตาผู้ใช้ได้
- อันดับเว็บไซต์ (SEO) อาจลดลง หาก GoogleBot ไม่สามารถเข้าถึงเนื้อหาสำคัญ เว็บไซต์อาจถูกมองว่าไม่มีข้อมูลที่เพียงพอ ส่งผลให้การจัดอันดับลดลง หรืออาจไม่ติดอันดับเลยก็ได้เช่นกัน
- ปัญหาด้านประสบการณ์ของผู้ใช้ (User Experience) หาก GoogleBot ไม่สามารถ Crawl หน้าเว็บได้ อาจเกิดปัญหาหน้าเสีย (Broken Links) ในผลการค้นหา และผู้ใช้ที่คลิกลิงก์อาจพบ 404 Page Not Found ทำให้ประสบการณ์ใช้งานแย่ลงได้
สรุป
GoogleBot คือบอตที่ทำหน้าที่รวบรวมและบันทึกข้อมูลเว็บไซต์ในระบบของ Google เพื่อให้สามารถแสดงผลในการค้นหาได้อย่างถูกต้องและแม่นยำ ซึ่งการปรับแต่งเว็บไซต์ให้เหมาะกับ GoogleBot ไม่ว่าจะเป็นการสร้าง Sitemap ตั้งค่า Robots.txt อย่างเหมาะสม เขียนเนื้อหาตามหลัก SEO และแก้ไข Error Pages อย่างสม่ำเสมอ จึงถือเป็นกุญแจสำคัญในการทำ SEO ให้มีประสิทธิภาพและช่วยเพิ่มโอกาสติดอันดับต้นๆ ในผลการค้นหาได้ในระยะยาวอีกด้วย
FAQ – คำถามที่พบบ่อย
Google Search คืออะไร
Google Search คือเครื่องมือค้นหาแบบอัตโนมัติ ที่ช่วยให้ผู้ใช้งานเข้าถึงข้อมูลจากเว็บไซต์ต่างๆ ทั่วโลกได้อย่างรวดเร็ว โดยใช้ Web Crawler สำรวจและรวบรวมข้อมูล จากนั้นจะนำข้อมูลที่ได้มาประมวลผลเพื่อแสดงผลลัพธ์ที่ตรงกับคำค้นหาให้มากที่สุด ซึ่ง Google Search เป็นเครื่องมือที่ได้รับการอัปเดตอย่างต่อเนื่อง จึงช่วยให้ผู้ใช้ได้รับข้อมูลที่แม่นยำและเป็นประโยชน์มากที่สุดในทุกการค้นหา
Google Bot vs Google Algorithm เหมือนหรือต่างกันอย่างไร
Google Bot และ Google Algorithm มีความแตกต่างกันทั้งในด้านจุดประสงค์และลักษณะการทำงาน ดังนี้
จุดประสงค์
- Google Bot : เป็นโปรแกรมรวบรวมข้อมูล (Web Crawler) ที่ Google ใช้เพื่อสำรวจและเก็บข้อมูลจากเว็บไซต์ต่างๆ ทั่วอินเทอร์เน็ต
- Google Algorithm : เป็นชุดของกฎและกระบวนการที่ Google ใช้ในการวิเคราะห์และจัดอันดับเว็บไซต์ในผลการค้นหา เพื่อให้ผู้ใช้ได้รับข้อมูลที่เกี่ยวข้องและมีคุณภาพมากที่สุด
หน้าที่และลักษณะการทำงาน
- Google Bot : ทำหน้าที่เข้าเยี่ยมชมเว็บไซต์ต่างๆ โดยการติดตามลิงก์จากหน้าเว็บหนึ่งไปยังอีกหน้าเว็บหนึ่ง เพื่อรวบรวมข้อมูลและนำไปจัดเก็บในดัชนีของ Google
- Google Algorithm : หลังจากที่ Googlebot รวบรวมข้อมูลและจัดเก็บในดัชนีแล้ว อัลกอริทึมของ Google จะทำการวิเคราะห์ข้อมูลเหล่านั้น โดยพิจารณาจากปัจจัยต่างๆ เช่น ความเกี่ยวข้องของเนื้อหา คุณภาพของเว็บไซต์ และประสบการณ์ของผู้ใช้ เพื่อจัดอันดับและแสดงผลการค้นหาที่เหมาะสมกับคำค้นหาของผู้ใช้
สรุปแล้ว Googlebot และ Google Algorithm เป็นโปรแกรมที่มีความแตกต่างกันในหน้าที่และวัตถุประสงค์ แต่จะทำงานร่วมกันโดยที่ Googlebot รวบรวมข้อมูลจากเว็บไซต์ และ Google Algorithm จะนำข้อมูลเหล่านั้นมาวิเคราะห์และจัดอันดับต่อ

